JavaScript Object Notation began as a means to transport data from server to browser in JavaScript, but has since become an independent standard and a predominant method used by RESTful Web Services such as the VirusTotal API to deliver payload data. When you query a RESTful API you are likely to get back either JSON or XML, and of the two JSON is simpler and lighter, and thus more common.
Most IT Systems and Security specialists have heard of JSON and probably seen examples, but many have never actively played with it programmatically. It’s a useful tool in the InfoSec tool bag and an essential one for extracting , manipulating and presenting data gleaned from APIs.
Referencing the HashChecker object from the 4th Python/Splunk series blog entry, we see that VirusTotal returns JSON. It’s easy to interrogate the JSON object and experiment with processing it using Jupyter. First, here is an example of how to check that the transaction was successful:

While it’s straightforward to retrieve and view all of the nested JSON from the query, it can be a bit of a jumble to organize and make sense of:

JSON object with no formatting
Using Python’s json module, it’s simple to improve the readability of the output and determine the logical structure of the data. The json.dumps method will dump out a string that can be indented for readability with the indent parameter:
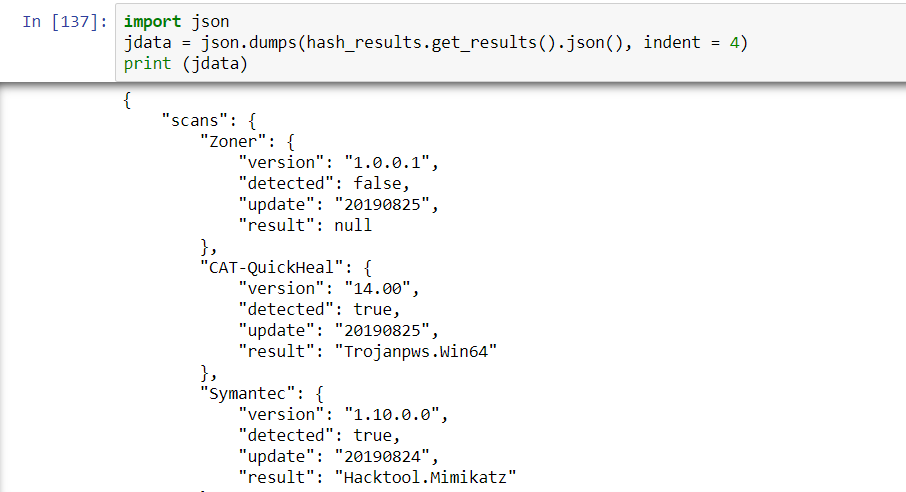
With this it’s possible to instantly see the logical structure of the response and see a way to quickly check the results for positive hits. As noted, if one checks the type of object that json.dumps() produces, it will turn out to be a string. Generically, JSON is a string. When you ingest JSON from the Requests object, it will be a dictionary.
print(type(jdata))
print(type(hash_results.get_results().json()))
Output of this: <class 'str'> <class 'dict'>
Since JSON is actually a string comprised of curly braces, commas, and brackets (similar to a Python dictionary), it’s easy to see how Python can ingest a nested JSON object as a dictionary object. Understanding the type makes it obvious as to how to interrogate the object. Returning to the positive hits question, let’s write the code to look at it:
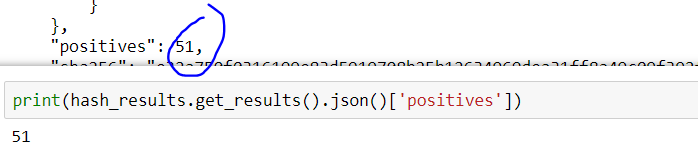
For the sake of demonstration, suppose we want to know if the AVG service detected a positive result from the hash–here is one-liner to achieve that by querying for the ‘AVG’ key in the nested dictionary based on the ‘scans’ level:

Understanding JSON more deeply and recognizing that the task of ingesting VT data into DataFrame is essentially ingesting a dictionary into a DataFrame, we can formulate more elegant code for the set_dataframe method — recall that this was previously an inelegant ‘slash and burn’ exercise into forcing a glob of data into the desired row/column format desired.
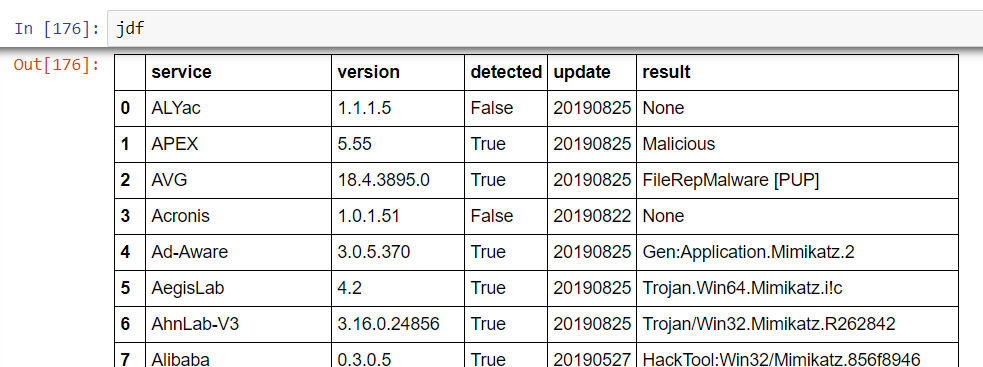
With improved comprehension of the logical structures involved, it’s now possible to rewrite the set_dataframe method in the HashChecker class without using a ‘for loop’ or transpositions. This is achieved using only a couple of lines–the new DataFrame is called jdf:
jdf = pd.DataFrame.from_dict(hash_results.get_results().json()['scans'], orient='index').reset_index()
jdf.rename(columns={'index':'service'},inplace=True)
The reset_index and rename methods are used so as not to end up with the service name as the index. The resulting DataFrame is now logically organized and ready to use.
The Jupyter Notebook used in this entry is available for download on github.