The National Vulnerability Database publishes complete CVE (Common Vulnerabilities and Exposures) information as a JSON-formatted data-feed that can be downloaded into a local repository such as MongoDB and/or processed via scripting. Here is a demonstration of how to easily manipulate, format and query this JSON with Python. Begin by downloading the JSON data feed file from the NVD site here.
You will note that the file is deeply nested and challenging to work with without a bit of manipulation. Creating a Pandas Dataframe is perfect for this. I suggest using a Jupyter Notebook to explore the data structure and understand how the nesting might need to be flattened or otherwise organized for your purposes. The Pandas and JSON modules will be very useful.
From a Python perspective, the JSON nesting consists of nested dictionaries. If you simply ‘cat’ or ‘more’ the data file on a command line it will look a bit tangled, but the JSON module helps import it in such a way as to facilitate flattening.
import json
import pandas as pd
# this is the downloaded JSON file from NVD
# from a Python perspective, it's a list of
# nested dictionaries and challenging to
# make sense of without some manipulation of the nesting
your_path = 'd://projects/scratch/'
nvd_file = 'nvdcve-1.1-modified.json'
with open(your_path + nvd_file) as json_file:
data = json.load(json_file)
# get rid of the first few lines of
# meta information and create a list
# of dictionaries keyed by cve information
cves = data['CVE_Items']
cves[0]
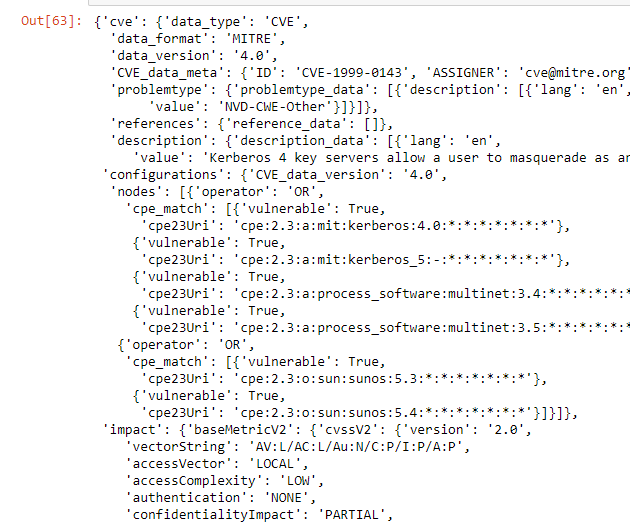
# notice the actual CVE # is buried
# in nested dictionary as CVE_data_meta:ID
print(cves[0]['cve']['CVE_data_meta']['ID'])
CVE-1999-0143
# extract all the numbers to build
# as a column in a dataframe
# simplest is to use a list comprehension for this
cve_number_list = [ sub['cve']['CVE_data_meta']['ID'] for sub in cves ]
df = pd.DataFrame(cves,index=cve_number_list)
# we would like a column that is CVE numbers rather than an index
df = df.rename_axis('cve_number').reset_index()
df
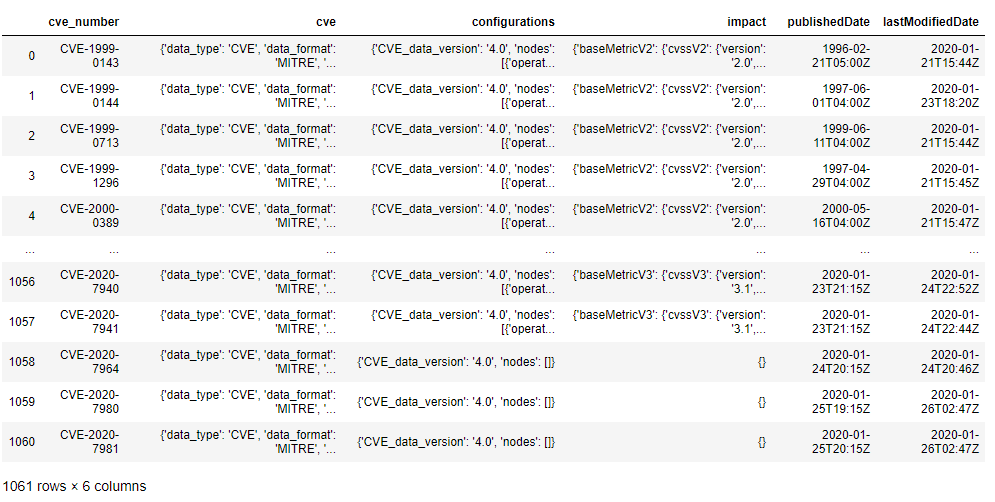
Now we have a nicely formatted Dataframe that allows for searching: here is an example of searching for CVE-2020-7980:
df.loc[df['cve_number'] == 'CVE-2020-7980']

Next time we will look at scoring via the vector that is nested in the ‘impact’ column as well as demonstrate how to do look ups on descriptions and scores.