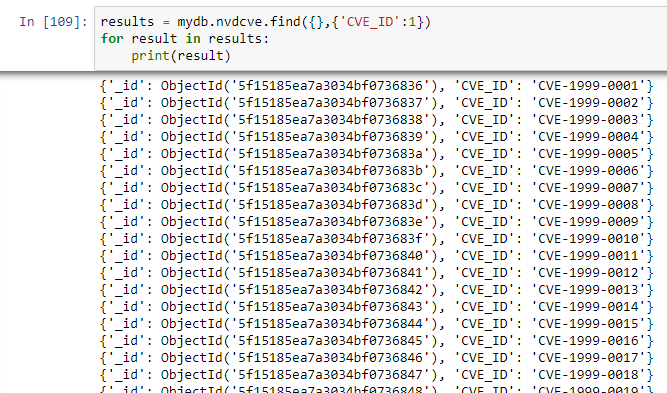
In the last entry we added an NVD file to MongoDB with an insert command from PyMongo. Hence, at this point we have a single yearly NVD file (2002) posted in to a MongoDB and we want to investigate if this is a useful way of managing the NVD data. Was this an optimal approach to managing a store of CVE data? Let’s review by querying what exists in the new MongoDB nvdcve collection:
The query can be done in Python, but a very convenient method to quick check the collection is through either a graphical MongoDB interface query tool or simply the command line mongo client that was installed with MongoDB. In this case, I simply use the mongo client to quickly query the collection:
db.nvdcve.find({},{id:1})
{ “_id” : ObjectId(“5f0bd7b9f9cdf5e2f0183be6”) }
db.nvdcve.find({},{id:1}).count()
1
If you expected that each CVE# would appear as a document–that was wishful thinking not immediately implemented in the structure of the downloaded document. Instead, there is one large document for the year containing all the year’s CVEs as sub-documents under one umbrella document ID.
This can be easily verified in Jupyter with Python code as well: using the find_one() method we see that there are 6748 CVEs listed under one document.
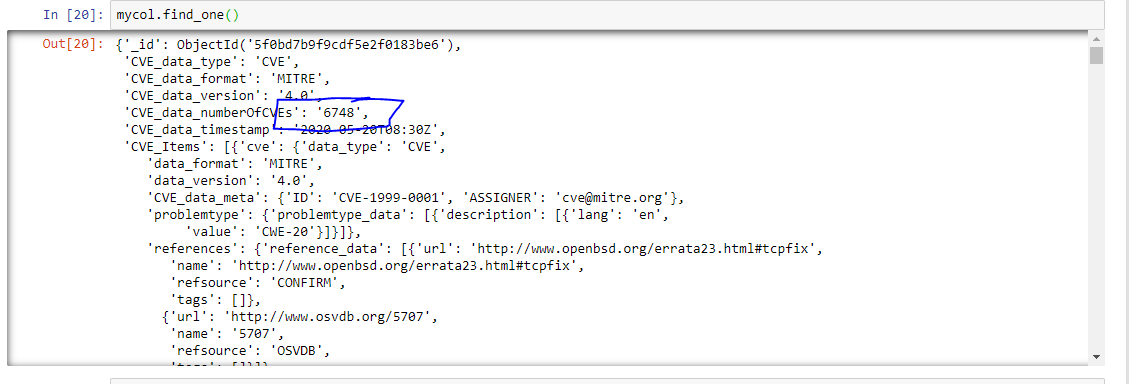
This format likely isn’t ideal. As an alternative, it’s simple to flatten out the nested JSON to where we could insert documents keyed by CVE#–given that is the way almost everyone searches and uses the NVD database. Recall earlier posts about flattening JSON–they will be useful for this task.
Below is a code example to flatten, clean-up some key names and insert into the collection.
#read the json file
with open('nvdcve-1.1-2002.json') as data_file:
data = json.load(data_file)
#normalize out the CVEs
df = json_normalize(data,'CVE_Items')
df.rename({'cve.CVE_data_meta.ID':'CVE_ID'}, axis=1,inplace=True)
#change the awkward index name
df.rename_axis('CVE')
#MongoDB doesn't like '.' in key names
df.columns = df.columns.str.replace(".", "_")
#insert records into MongoDB
result =mycol.insert_many(df.to_dict('records'))
This produces the below document count, which is likely more amenable to working with CVEs.
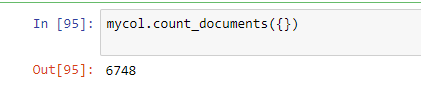
As demonstrated below, this structure more intuitive to work with and query against.