The opensource jq utility is an enormously handy tool for quick-and-dirty parsing of JSON files or feeds. The tool was created by Stephen Dolan in 2012 as a lightweight C-program. Its available for free download on various platforms including Windows, Mac and Linux. jq is particularly well-suited for lightweight and quick ETL-type work frequently undertaken by security specialists working in data-intensive environments.
The tool’s usage and style will be familiar to those accustomed to working in Linux or other Unix distributions–it’s similar to the sed/awk/grep genre of parsing utilities. Feeding JSON into jq with few or no options at all will result in it ‘prettifying’ text into a nicely-formatted, colorized output that is much easier to read and to gain a sense of the document organization. Investing time in learning it’s more advanced functions will be worthwhile to those who routinely deal with JSON feeds.
There are various YouTube and webpage tutorials to aid in learning the tool. In addition, there is a wide community of support–if you run into an issue, chances are you will find it asked and answered on a forum somewhere. The purpose here is to introduce some examples to see how it can be useful to those of us with in a security niche who may have not run into it previously
Some Examples
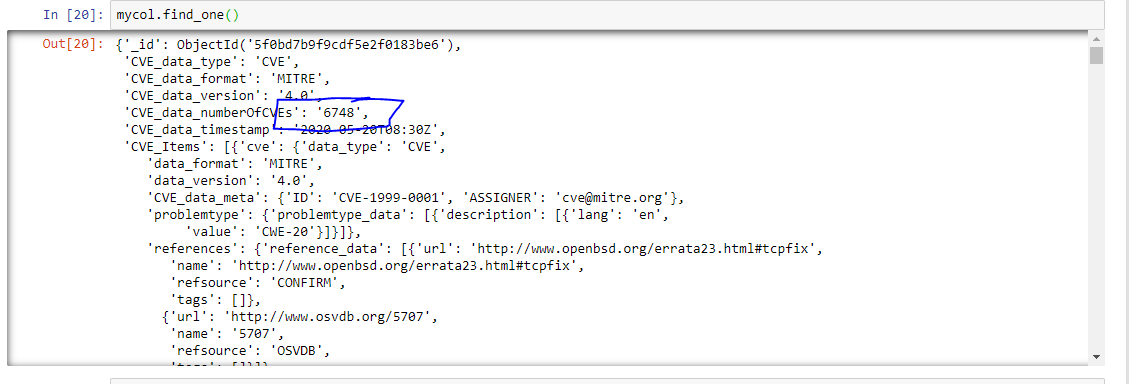
Looking back at the JSON CVE feed files from NVD discussed in the last few blog articles, it’s simple to find useful places where one can apply jq. In our first example we use jq with no options (except colorize) to format and NVD JSON file:
rzupancic@tiserver:~/CVE$ cat nvdcve-1.1-2009.json | jq -C
{
“CVE_data_type“: “CVE”,
“CVE_data_format”: “MITRE“,
“CVE_data_version”: “4.0“,
“CVE_data_numberOfCVEs“: “5001“,
“CVE_data_timestamp”: “2020-11-24T08:56Z“,
“CVE_Items”: [
{
“cve”: {
“data_type”: “CVE“,
“data_format”: “MITRE“,
“data_version”: “4.0“,
“CVE_data_meta”: {
“ID”: “CVE-2009-0001“,
“ASSIGNER”: “cve@mitre.org“
Later on we will discuss the field in bold above–CVE_data_numberOfCVEs–in an advanced example.
Compare the above output to the raw output of cat’ing the file and you will see an immediate benefit of jq. The formatting is nice for getting an overview of the data–a quick view of the data’s keys and nesting. Harnessing the real power of the utility requires acquiring some basic proficiency in navigating the data’s keys and arrays together with the utility’s filtering options and built-in functions.
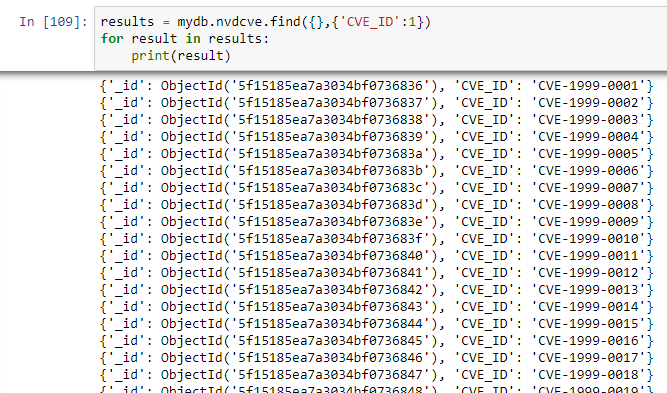
In the next example, also using the NVD JSON files, suppose one wanted to parse out and view all of the CVE ID’s–we introduce the use of a filter:
rzupancic@tiserver:~/CVE$ cat nvdcve-1.1-2009.json | jq -C .CVE_Items[].cve.CVE_data_meta.ID
“CVE-2009-0001”
“CVE-2009-0002”
“CVE-2009-0003”
“CVE-2009-0004”
“CVE-2009-0005”
“CVE-2009-0006”
“CVE-2009-0007”
“CVE-2009-0008”
“CVE-2009-0009”
“CVE-2009-0010”
“CVE-2009-0011”
“CVE-2009-0012”
“CVE-2009-0013”
Other keys can be added to the query filter to selectively add complexity and delve deeper into an investigation of the CVEs–all within a single command line.
JQ with Web Services
To demonstrate how to grab data directly from a web service, here is an example of using the curl utility together with jq to easily parse an API call on a SecurityTrails whois API feed–in this case to capture the nameservers of a domain. Note that this example, as well as the last, takes into account the use of arrays in JSON to organize data as ordered sequences–hence the use of brackets to dereference arrays in addition to the periods that dereference keys (as in key/value pairs).
rzupancic@tiserver:~/CVE$ curl –request GET –url https://api.securitytrails.com/v1/history/grumblesoft.com/whois –header ‘apikey: <here>’ | jq .result.items[0].nameServers
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 6321 100 6321 0 0 3967 0 0:00:01 0:00:01 –:–:– 3967
[
“NS41.DOMAINCONTROL.COM”,
“NS42.DOMAINCONTROL.COM“
An Advanced Example
Finally, to see something slightly more advanced, suppose you are wondering what the total CVE count is in the combined set of NVD JSON files is. One of the fields from the NVD JSON file, listed above, was CVE_data_numberOfCVEs, which can be used to add the total CVEs in all files together. Here’s an example in the shell:

This calculates the total CVEs from all yearly JSON (as of a point in time–this changes)-153,671. This uses a tonumber conversion function and a summing routine. The line of code in the shell capture above is:
cat *json | jq ‘.CVE_data_numberOfCVEs|tonumber’ | jq -n ‘[inputs | . ] | reduce .[] as $num (0; .+$num)’