Finishing off the discussion of NVD JSON mirroring: there is a repository available for download here via github including a Jupyter Notebook that contains all of the functionality discussed in the various NVD-CVE blog posts.
To start using the Notebook you must install Mongodb: follow the steps below as a rough roadmap–there are countless platform specific, step-by-step guides available as references on how to install and get started with a Mongodb instance.
- Install MongoDB
- Create a database named nvd with two collections: maincol and modscol
- Create a user than can admin the above db and collections
- Determine a configuration directory where you will place an environment file for connecting to your mongodb instance
- Determine a working directory for downloading the NVD files
- Place a file named “.mongo.env” in the configuration directory of choice (e.g. your home directory). The structure of this file is described in the Jupyter Notebook
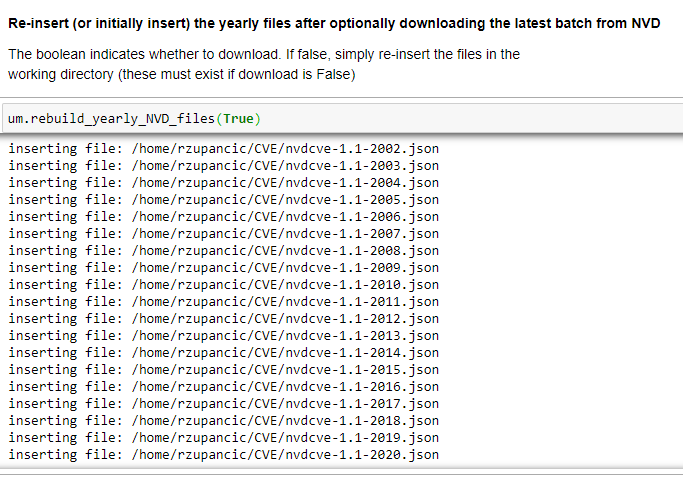
To begin, the code contains a method (see below) to download and insert the NVD JSON yearly files into the maincol collection. Next there are routines to update this main collection of CVEs with the modification file that NVD provides. NVD suggests initially downloading the yearly files, then updating them by periodically applying the modifications file–the modifications file will contain both revised and new CVEs. A reasonable automated schedule might be to re-download and reload the nvdcve-1.1-modified.json.zip file once or twice per day. The modifications file goes back eight days–If not reapplied at least every eight days it will fall too far behind. If that happens, the yearly files will need to be re-downloaded and reloaded.
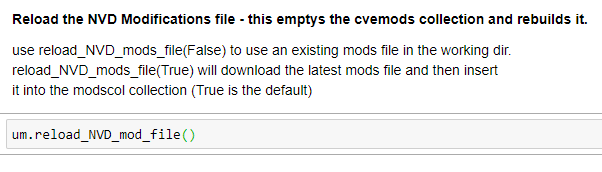
The example images below depict an invocation of the method to load/reload the yearly files from NVD onto your local mirror, and then a method to reload the modification file. In the code below, um is an instance of the UpdateMongo Class defined in the Notebook.
Apply the Modifications File
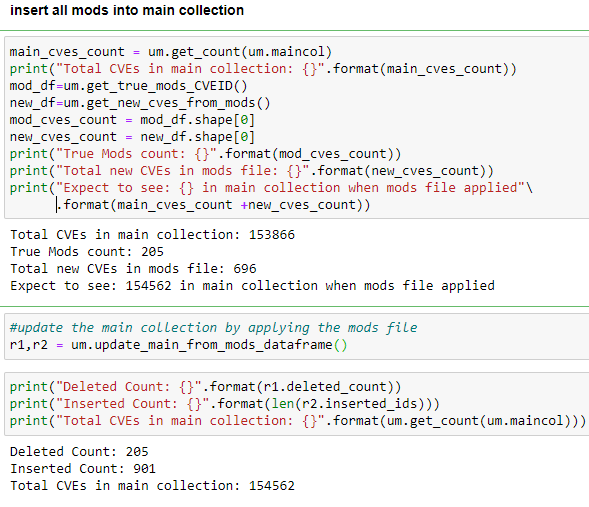
In order to keep the main collection of CVEs updated, the modifications file must be frequently updated and applied to the main collection. The modifications file, recall, has both new and modified CVEs in it. Applying it essentially means avoiding duplicates by updating CVEs that exist in the main collection, and adding brand new CVEs that exist in the mods file but not in the main collection. The Class method:
<em><span style="color:#389ec0" class="has-inline-color">update_main_from_mods_dataframe()</span></em>
does this. It has ‘dataframe’ at the end of its name to designate that it uses Pandas DataFrames to determine what is common in each collection–versus pymongo routines. I tend to rely on Pandas for anything that looks like ETL (Extract, Transform, Load).
Download the github repository containing the code, install Mongodb, and follow along in the Notebook to insert and manipulate your CVE mirror. If you can get through the various steps to the point of adding customization for your own environment, you will have become at least somewhat proficient in using Mongodb, Python and Pandas.
What’s Next?
CVE repositories are most useful when you can add environmental components to the scoring as well as Threat Intelligence. The next exploration demonstrates adding more information and local context through a TI and Asset Discovery layer.