NIST’s National Vulnerability Database site maintains a collection of json files that comprise the entire historical repository of CVEs from the beginning of the CVE era (1999) up to the current day. This data is available in the public domain, and it can be systematically downloaded to maintain a local mirror.
This is the first in a series of articles that will demonstrate how to implement a local mirror of NVD data and manipulate this data for your organization’s purposes.. The NVD site maintains the data as a collection of yearly files (plus some ongoing ‘catch-up’ files) . The JSON data repository is located here.
Why Build a Mirror
There are various good reasons why a local repository may be useful:
- Creating a daily report on new incoming CVEs
- Easily searching or reporting on the data, or combining the CVEs with other local data for reporting.
- Feeding a daily process that ties a Threat Intelligence (TI) feed to the CVEs and ranks their importance on your Enterprise.
- Combining the feed with Environmental components from findings on an Enterprise.
Most organizations rely on their scanning platform to rate severity and priority–this is usually based on CVSS3 scores. This approach is a good start, but it may not be enough. Augmenting the data with threat intelligence streams not available via the platform’s plugin feed may be a requirement. Finally, the price of the NVD data stream is right–as mentioned, it is available for the taking. Aggregated with various low-cost streams, this is a compelling advantage given that some CVE data streams can cost hundreds-of-thousands of dollars per year.
An organization may find it more effective to re-score findings based on environmental considerations. Scanning platforms are not going to figure in an Environmental component, even when those platforms can augment CVE Base scores with a Temporal score based on TI.
Getting the Data
That is the case for why this may be useful. Exploring how to go about using this: The first step is to download the yearly data using some simple scripting:
def get_NVD_files(d_path):
'''Public method to download NVD datafiles in zip format, the URL is:
https://nvd.nist.gov/feeds/json/cve/1.1/nvdcve-1.1-[year].json.gz
inputs: d_path - directory path as string
'''
for year in range(2002,2020):
file = 'nvdcve-1.1-' + str(year) + '.json.zip'
#need the URL, which for NVD files is an embedding of the year
url = 'https://nvd.nist.gov/feeds/json/cve/1.1/' + file
f = requests.get(url, allow_redirects=True)
#save the file
f_path = d_path + file
open(f_path, 'wb').write(f.content)
f.close()
Exploring the Data
Next, it’s instructive to take a look at this data and examine how it is formatted. Pandas seems a reasonable choice to load in some data for exploration. You may want to refer back to a previous article on viewing JSON data with Pandas. Using a Jupyter Notebook is perfect to interactively examine it. Here we take a couple of years data and aggregate it into a DataFrame.
taking a look at a few years with a Pandas DataFrame
cve_df = pd.DataFrame()
for year in range(2002,2005):
filename = 'nvdcve-1.1-' + str(year) + '.json.zip'
f_path = "D:/projects/NVD/" + filename
#read into a temp dataframe and then aggregate
df = pd.read_json(f_path, orient='columns', encoding='utf-8')
#now aggregate it into a running total
#cve_df = pd.merge(cve_df, df, left_index = True, right_index = True, how = 'outer')
cve_df = cve_df.append(df,ignore_index=True)
Taking a look at this DataFrame in Jupyter: it has 10998 rows and only 6 columns:
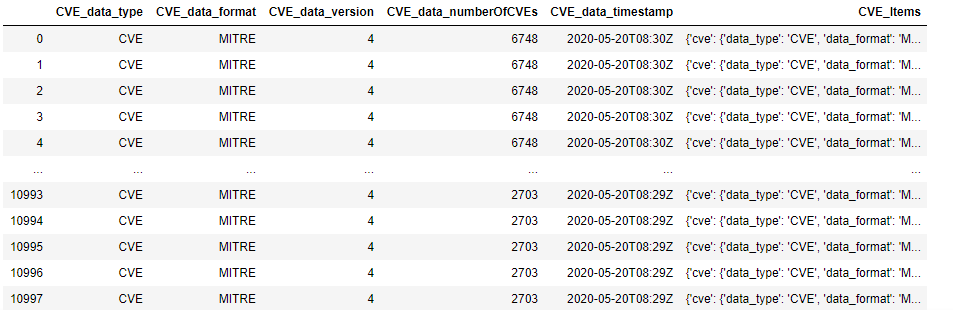
Taking a look at row 0 should allow us to look at the very first CVE. It is clear from the above that the interesting information is deeply nested in column 5–the CVE_Items columns The command to do this is simply cve_df.iloc[0,5]:
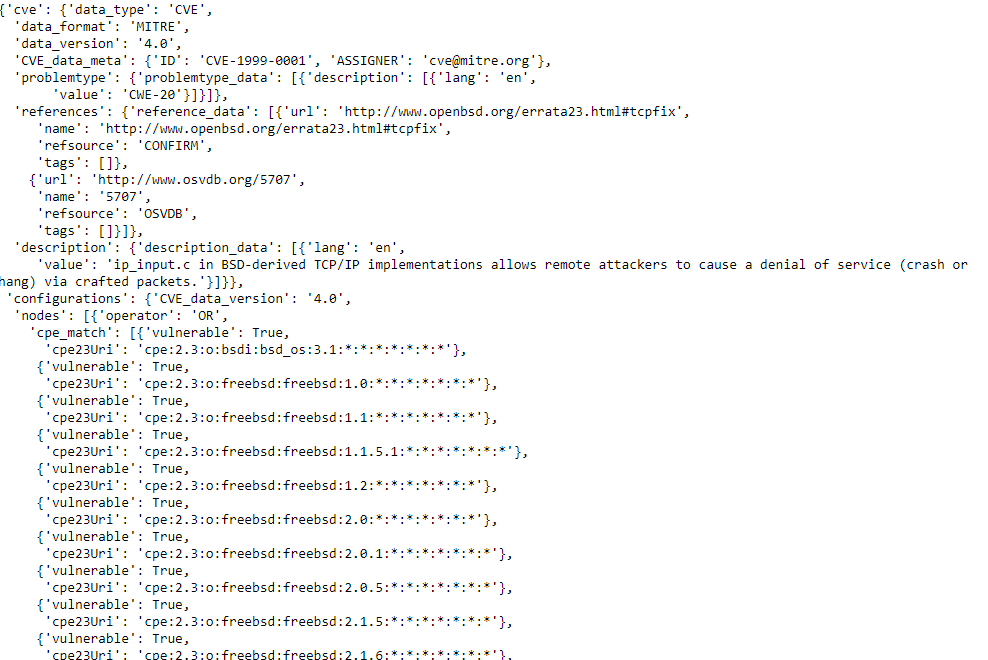
The CVE_Items column is deeply nested JSON–this amounts to a deeply nested dictionary in Python. It would possible to flatten these dictionaries into a dataframe with a lot of columns, but the first problem is readily apparent: the cpe_match list has an arbitrary number of dictionaries. If flattened completely, the result will be an arbitrarily large number of columns that differ from CVE to CVE, and the DataFrame will be unwieldy and not that helpful.
Conversely, if no flattening occurs, the most interesting information including the CVE# will be deeply nested inside dictionary objects. So, what is the best approach? There are various options to explore:
- Completely flattening the nested JSON
- Partially flattening the JSON and storing in a Relational Database.
- Storing the data as JSON and rendering it in partially flattened DataFrame might be a path to pursue.