The task of creating voluminous lists of generated data for testing can be arduous if one starts from scratch programmatically. Generating 20,000 or so realistic names, for example, is challenging if you want the names to be realistic and unique. The same is true for locations. However, such a task is a relative breeze if one installs and learns to use a good random data generator library.
An example that I have used of late is the faker module for Python. One can create endless lists of generated names, IDs, serials, locations including zips and city/country, etc and match these to weighted lists of specified values such as departments or equipment type. Suppose a list of 20,000 names and employee IDs needs to be spread across a weighted distribution such as 10% sales, 10% marketing, 20% research, 40% warehouse. Using np.random.choice and the fake-factory this becomes simple.
def dept(self):
depts = [‘Marketing’,’IT’,’Sales’,’Research’,’Warehouse’]
# weights of choices in order or depts
p_dist = [.1,.2,.1,.2,.4]
# return a weighted random choice
return np.random.choice(depts,size=1,p=p_dist)[0]
However, creating this as provider class and integrating with the ability to create randomized name lists for thousands of objects is harder. Faker does that for us.
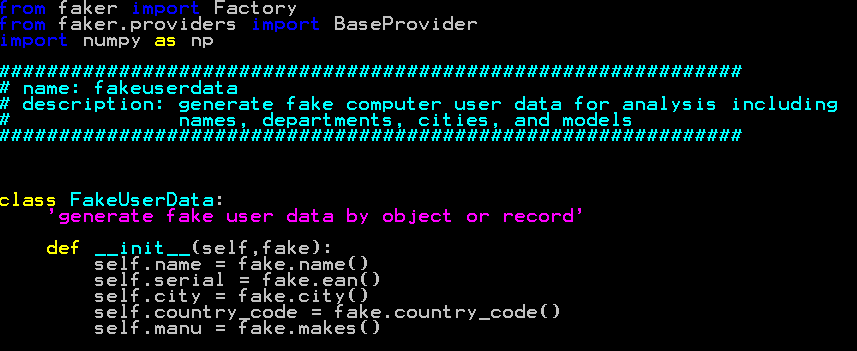
Here is a quick list of employees generated with faker as the core:
Christopher Sharp,5035341812376,Buchananburgh,ER,Apple
Christopher Shaw,6852349930500,Levinefort,AU,HP
Shannon Ray,1147556676996,Amandahaven,IS,Lenovo
Heather Lee,0822069553149,Higginston,CO,Lenovo
Samuel Hernandez,4779389153831,Brownfurt,LK,Dell
Mary Little,8310074570012,South Michaelbury,ME,Lenovo
Kelsey Munoz,1154029900069,West Brittanyfurt,IE,Dell
Toni Larson,6596085286537,Campbellfort,NA,Lenovo
Michael Oliver,4952428472401,Elizabethborough,RS,Lenovo
Jamie Morrison,1395021567373,Louisstad,BS,Lenovo
Melvin Parker,7496896418990,Lake Christopher,RU,Dell
Amy Ramirez,8320231525274,Port Andrewview,SO,Dell
Mark Morris,5569775848620,Robertstad,SN,HP
Kimberly Bryant,3424731814526,Richardtown,KN,Dell
…
This requires a few minutes of effort including adding a set of customized provider classes (e.g. a weighted set of organizational departments) to the existing random generators. This library has saved me vast amount of time and allowed for quick customization of large dataset generation. I thought others might find the example useful. Get the sample code at Github.